Недостаток kNN в том, что максимум может достигаться сразу на нескольких классах. В задачах с двумя классами этого можно избежать, если взять нечётное k. Более общая тактика, которая годится и для случая многих классов — ввести строго убывающую последовательность вещественных весов wi, задающих вклад i-го соседа в классификацию:

Выбор последовательности wi является эвристикой. Если взять линейно убывающие веса  , то неоднозначности также могут возникать, хотя и реже (пример: классов два; первый и четвёртый сосед голосуют за класс 1, второй и третий — за класс 2; суммы голосов совпадают). Неоднозначность устраняется окончательно, если взять нелинейно убывающую последовательность, скажем, геометрическую прогрессию: wi = qi, где знаменатель прогрессии q ∈ (0,1) является параметром алгоритма. Его можно подбирать по критерию LOO, аналогично числу соседей k.
, то неоднозначности также могут возникать, хотя и реже (пример: классов два; первый и четвёртый сосед голосуют за класс 1, второй и третий — за класс 2; суммы голосов совпадают). Неоднозначность устраняется окончательно, если взять нелинейно убывающую последовательность, скажем, геометрическую прогрессию: wi = qi, где знаменатель прогрессии q ∈ (0,1) является параметром алгоритма. Его можно подбирать по критерию LOO, аналогично числу соседей k.
Недостатки простейших метрических алгоритмов типа kNN.
• Приходится хранить обучающую выборку целиком. Это приводит к неэффективному расходу памяти и чрезмерному усложнению решающего правила. При наличии погрешностей (как в исходных данных, так и в модели сходства ρ) это может приводить к понижению точности классификации вблизи границы классов. Имеет смысл отбирать минимальное подмножество эталонных объектов, действительно необходимых для классификации.
• Поиск ближайшего соседа предполагает сравнение классифицируемого объекта со всеми объектами выборки за O(ℓ) операций. Для задач с большими выборками или высокой частотой запросов это может оказаться накладно. Проблема решается с помощью эффективных алгоритмов поиска ближайших соседей, требующих в среднем O(lnℓ) операций.
• В простейших случаях метрические алгоритмы имеют крайне бедный набор параметров, что исключает возможность настройки алгоритма по данным.
Некоторые метрики
Скалярное умножение векторов:

где p - размерность признакового пространства.
Абсолютное значение вектора (норма):
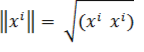
Направляющие косинусы:

Расстояние Танимото:

Содержание отчета
Отчет должен содержать:
1. Постановку задачи.
2. Таблицу 1 с обучающей и контрольной выборкой, графическое отображение выборок и эталонных значений.
3. Таблицу с результатами классификации реализованными алгоритмами (эталона и kNN) с использованием всех метрик обучающей и контрольной выборок и для различных k. Результаты классификации также отобразить графически.
4. Оценки обобщающей и распознающей способностей классификаторов.
5. Выводы. В выводах необходимо проанализировать, при использовании какой из метрик результаты классификации точнее и почему (как это связано с пространством информативных признаков), оценить компактность расположения точек на графике, оценить влияние компактности точек на работу методов.
6. Листинг программы.
Лабораторная робота №2
Тема: исследование классификатора на основе опорных векторов. Выбор ядра.
Цель: научиться использовать библиотеки для построения классификатора на основе опорных векторов, приобретение навыков анализа эффективности работы классификатора с использованием различных ядер.
Порядок выполнения работы
1. Скачать библиотеку LIBSVM со страницы http://www.csie.ntu. edu.tw/~cjlin/libsvm.
2. Разработать программу, реализующую SVM-классификацию с возможностью выбора ядра (одного из стандартных, предоставляемых библиотекой LIBSVM). Предусмотреть визуализацию обучающих данных и классификации по двум признакам.
3. Обучите SVM-классификатор, используя различные ядра и отобразите сгруппированные данные.
4. Протестировать и отладить работу программы на различных обучающих данных. Для чего необходимо выполнить следующее:
a. загрузите данные со страницы http://archive.ics.uci.edu/ml/datasets/Iris для классической задачи классификации ирисов Фишера (БД содержит 150 примеров с 5 признаками);
b. создайте двумерный массив, в котором в первом столбце хранятся измерения sepal length, во втором – sepal width для 150 ирисов;
c. Из вектора species, создайте новый вектор-столбец groups, чтобы классифицировать данные в две группы: Setosa и non-Setosa;
d. Наугад выберите обучающее и тестовое множества.
5. Оформить отчет по лабораторной работе.







